Guide 1: introduction
Overview
This series of “How To?” guides will take you through discrete aspects of working with Hospital Episode Statistics (HES), National Pupil Database (NPD) and social care data in ECHILD. Each one tackles a particular problem, providing hints and warnings as well as example code that you are free to copy, use and adapt however you wish.
Each guide should really be read in order as they follow on from each other. They aim to create a dataset that will enable you to answer the hypothetical research question: What is the association between chronic health conditions identified during primary school and exam results, absences, exclusions and non-enrolment in secondary school, accounting for demographic factors, social care involvement and special educational needs provision? We are keeping this question broad so that we can use it to highlight different aspects of ECHILD, and different ways of doing things, as we go along.
The general approach is depicted in Figure 1. We will carry out a longitudinal study and include anyone enrolled in year 7 in academic years 2014/15 to 2016/17 (and who therefore were born in 2002/03 to 2004/05) and who linked to any HES record. We will use HES admitted patient care records across primary school for our chronic health condition codes and we will use NPD across primary school for the covariates. The outcomes will come from Key Stage 4 (KS4) data, absences, exclusions and enrolments.
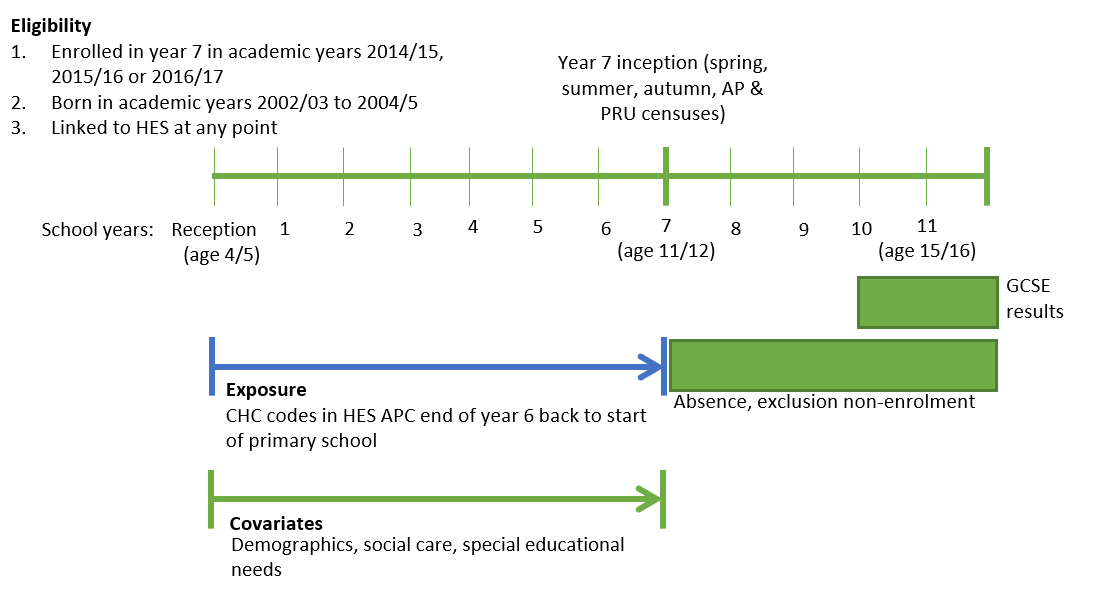
The approach depicted in Figure 1 represents a school inception cohort. We will also show you how you can alternatively create a cohort based on birth records in the HES admitted patient care data. Whether you start with a school or HES cohort, however, the general approach to data extraction will be the same, described in more detail in Guide 3 – Identify a cohort and create a cohort spine.
We have not attempted to provide the best approach scientifically. For example, we do not take account of health exposures or covariates during the secondary school years. We completely ignore the pre-school period. Instead, this example is designed to show how to manage the data to create an analysis-ready dataset. Exactly what those analyses are and what that dataset is, is of course up to you.
These guides make use of the following modules of data:
- NPD censuses, including the autumn, spring and summer censuses and the alternative provision and pupil referral unit censuses
- HES admitted patient care records
- HES outpatient data
- NPD exclusion data
- NPD absence data
- NPD KS4 data
- Children’s social care (CSC) data
Not all projects need access to all data and so you may not be able to reproduce all scripts exactly as they are given in these guides. Additionally, there are datasets we have not used, such as exams results from other Key Stages or the early years data. While these guides are not exhaustive of everything you can or should do with ECHILD, we hope that they will serve as a useful starting point and reference to support you in your data management and analyses.
The scripts
We will create an analysis-ready dataset across several guides, each with its own R script or scripts. You can download the scripts using the links in Table 1, below, or at the start of each guide.
You will notice that we do not have a script for extracting and cleaning children’s social care (CSC) data. This is because we have already produced and published CSC data extraction and cleaning code that produces cleaned datasets. We will use this cleaned dataset to very easily extract some flags into our cohort. This is dealt with via code in Guide 11 whereas Guide 12 discusses the CSC data more generally.
How much R do I need and what version?
These guides assume at least a basic working knowledge of R. Throughout we try to explain the more unusual and trickier concepts in detail. Because we have used only two packages, both of which are very widely used, we hope that the code provided here will prove robust to updates to R. The code was all developed and tested inside the ONS Secure Research Service using R 4.4.0.
Coming up…
Guide 2—Script management, coding principles and working in the SRS—will take you through some preliminary matters for working with ECHILD on the SRS, including where to the find the data, how to run SQL queries, the importance of modular coding and how we have set up the working directory and other matters that will be used throughout all the guides.